Want to win $1,000,000 for your data science skills?
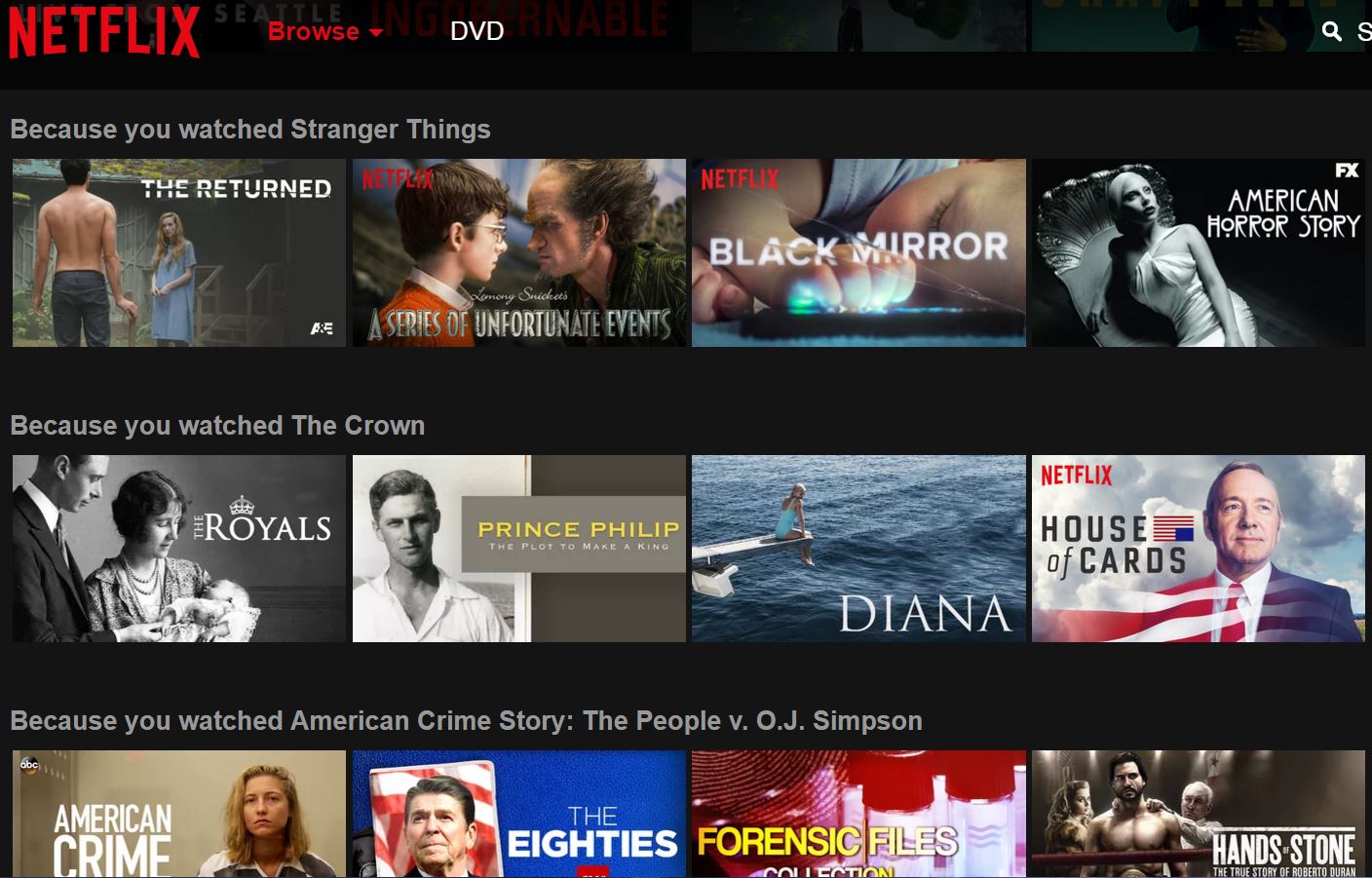
Recommendation Systems
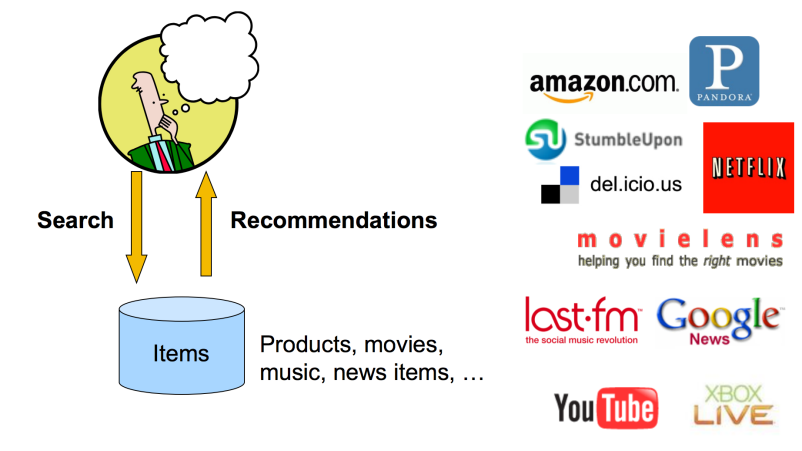
Naive Approaches
- Hand curated
- Aggregates
Problems with these approaches?
Content based approaches
Idea: Recommend items to customer X that are similar to items that customer X rated highly
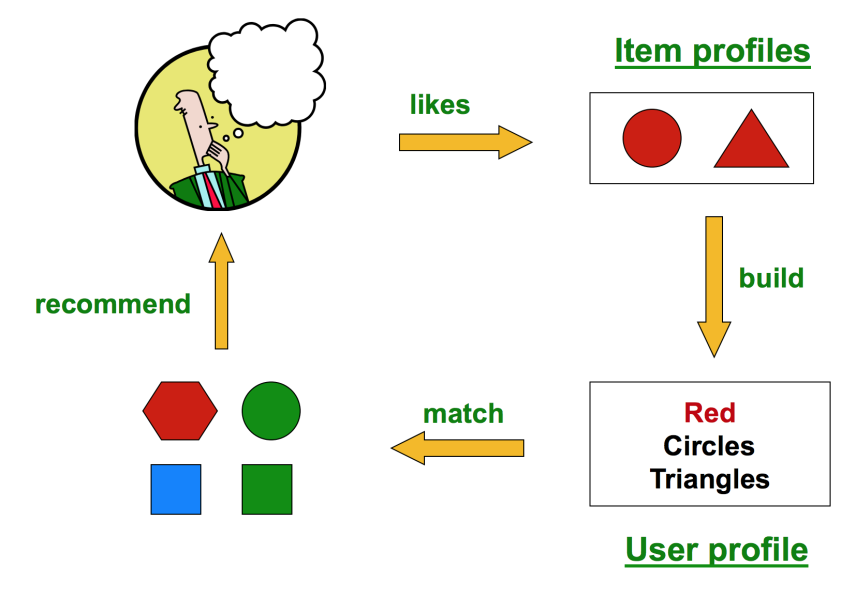
Content based approaches
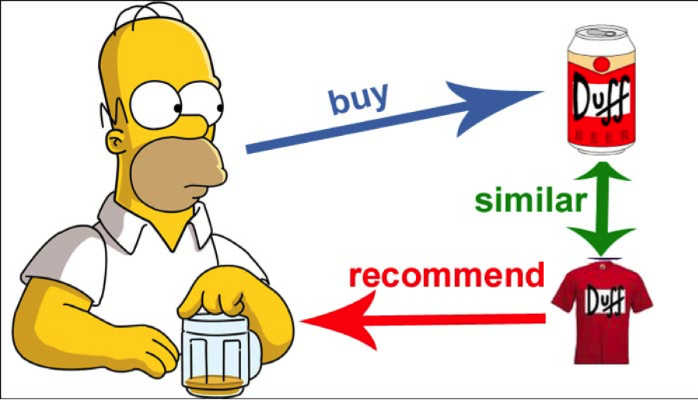
Content Filtering
Creates a profile for each user or product
- User: demographic info, ratings, etc.
- Item: genre, actor list, etc.
Advantages
- No need for data from other users
- Able to recommend new items (no first rater problem)
Problems?
Cold start
Determining appropriate features is difficult
Implicit information
Better: Collaborative Filtering
Relies only on past user behavior (doesn’t need explicit profiles)
Domain free
Generally more accurate than content based-approaches
Problems?
Cold start: If there is no previous behavior for that user and no explicit profile, how can you make a suggestion?
Alternatively, what about a new product?
Types of Collaborative Filtering
- Neighborhood methods: compute relationships between items or users
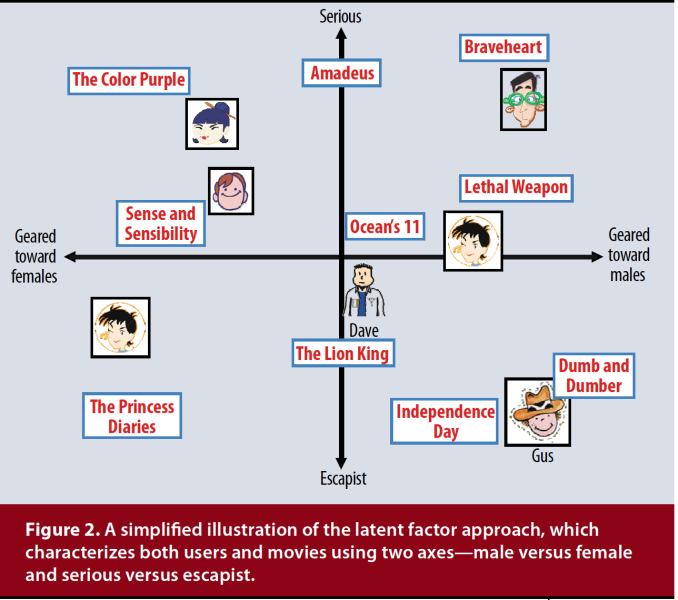
- Latent factor models: explains the ratings by characterizing items and users by small number of inferred factors
Problems with Neighborhood methods
Expensive to find the nearest neighbor!
Empirically, not as good as latent factor models
Latent Factor models (Matrix Factorization)
Characterizes both items and users by vectors of factors inferred from item rating pattern
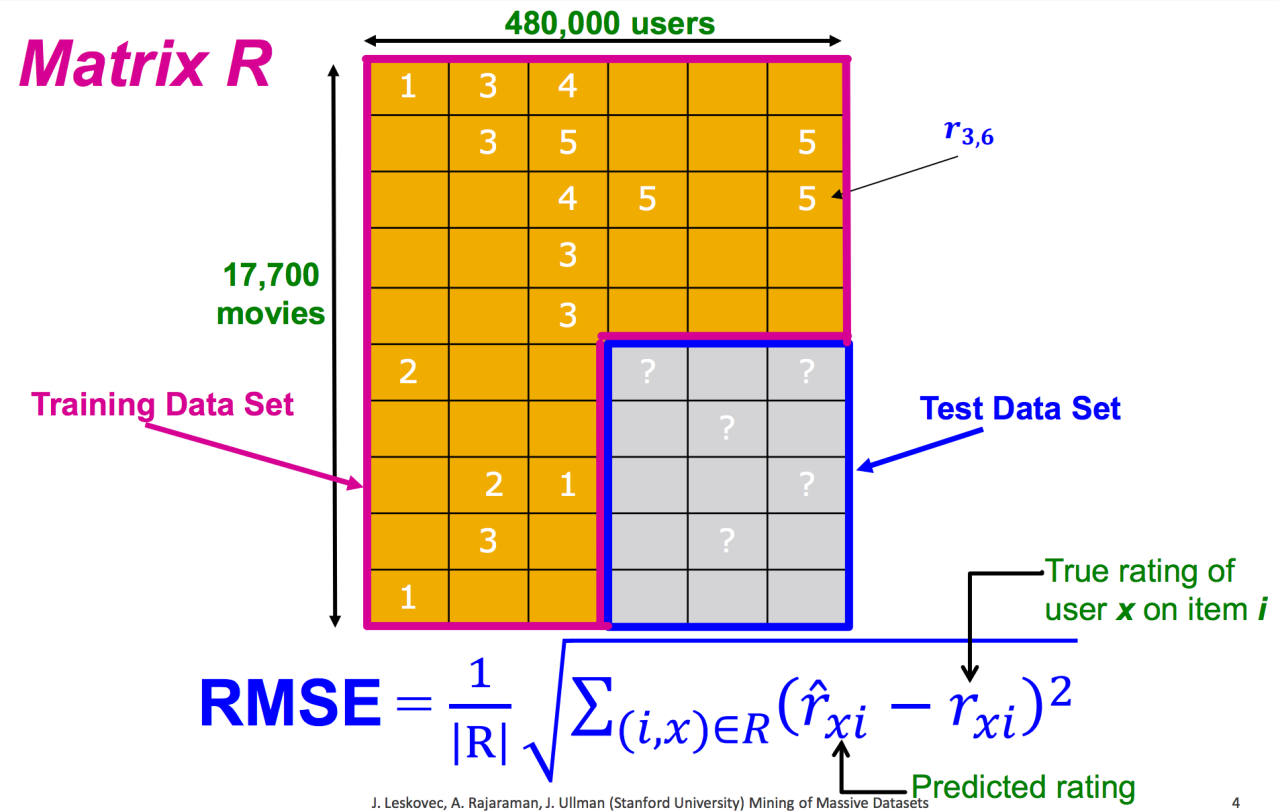
Explicit feedback: sparse matrix
Good scalability
Intro to Matrices
Ratings Matrix
Matrix Factorization
Low-rank assumption: a few factors characterize the users and items (k << n)
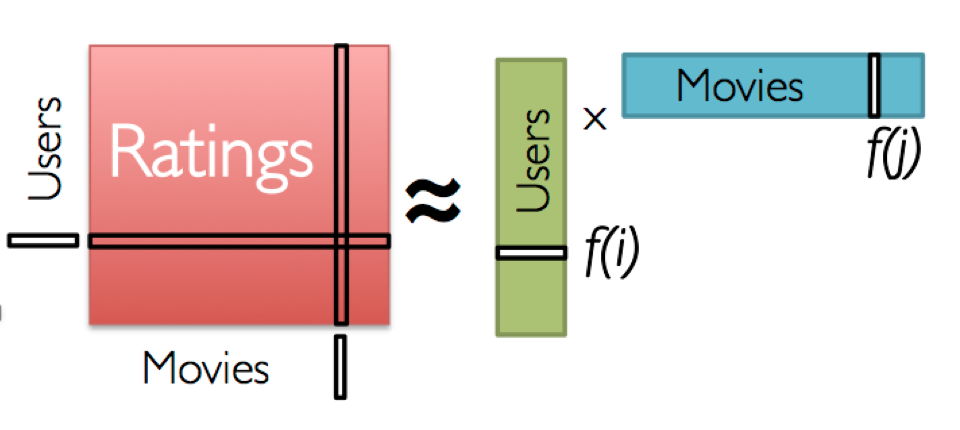
Alternating Least Squares (ALS)
- Randomly initialize user and movie factors
- Repeat:
- Fix the movie factors, and optimize user factors
- Fix the user factors, and optimize movie factors
$\min_{q*, p*}\sum_{(u,i) \in R} (r_{ui} - q_{i}^Tp_{u})^2 + \lambda(||q_{i}||^2 + ||p_{u}||^2)$
Why not use SVD?
Answer: Too many missing entries, and imputation is expensive or inaccurate
Naive ALS
Broadcast R, U, V
- R: ratings matrix
- U: user factors
- V: item factors
Problems?
Storing R
R is a very large matrix and possibly won’t fit in main memory
Sends duplicate copies to each worker
Distribute R
Store R as an RDD/DataFrame, but broadcast U and V
Problems?
Storing U and V
U and V might not fit in memory either
Sends duplicate copies to each worker
Join ALS
Store R, U, and V as an RDD/DataFrame
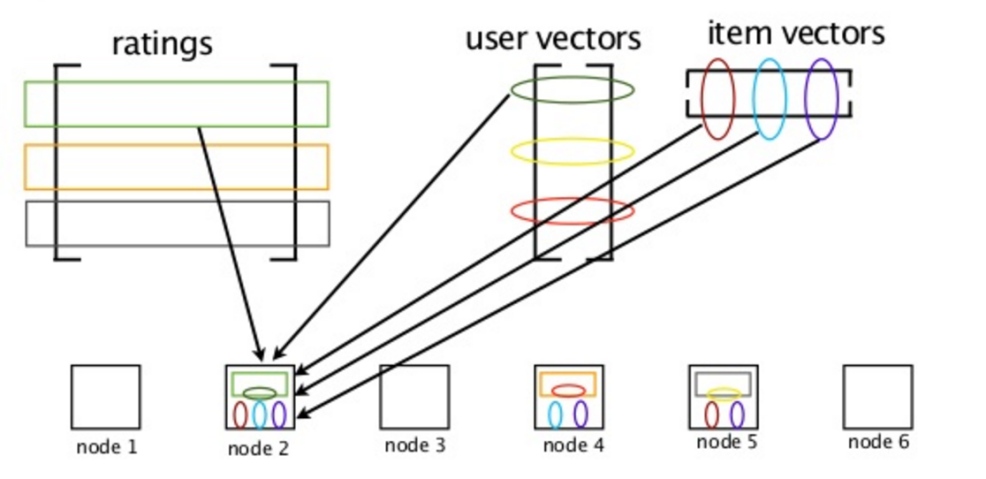
Blocked Join ALS
Spark implements a smarter version of join ALS to limit data shuffling
ALS is an example of a distributed model (i.e. stored across executors)