K-Nearest Neighbors
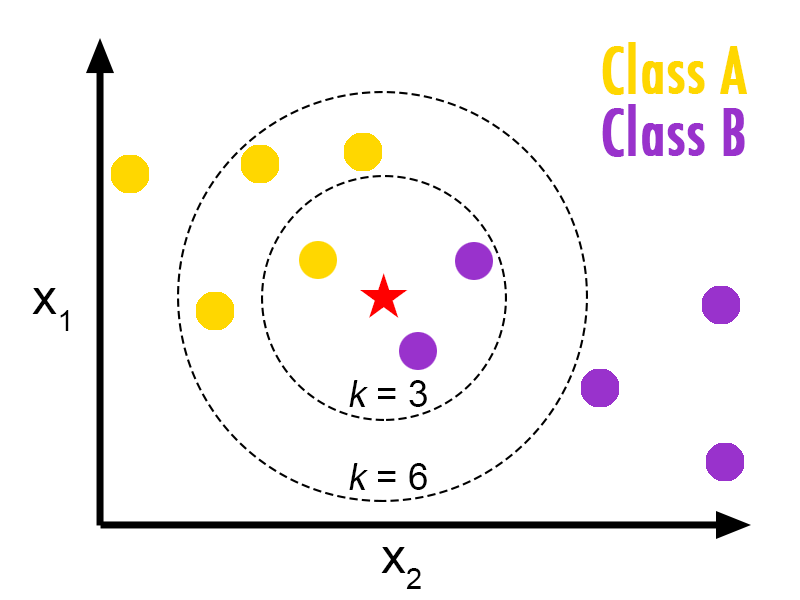
For a given test point, find the k closest training points.
Take the label of the majority
Distance Metrics
Manhattan
Euclidean
Training time?
Unlike most other algorithms, KNN doesn't require any training!
Trade-off: Relatively large test time
Choosing the optimal k
When k increases, decision boundary becomes smoother
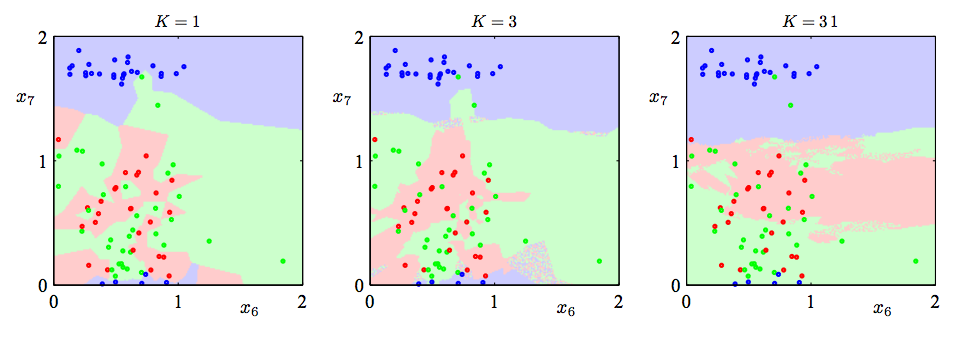
Question
What would your error be if you use the same dataset for training and testing, and set k=1?