Machine Learning Deployment
What is ML Deployment?
The 4 Deployment Paradigms
Deployment Requirements
Deployment Architectures
Other Issues
What is ML Deployment?
Data Science != Data Engineering
Data science is scientific
- Business problems -> data problems
- Model mathematically
- Optimize performance
Data engineers are concerned with
- Reliability
- Scalability (load parameters)
- Maintainability
- SLA’s
- ...
Closed Loop Systems
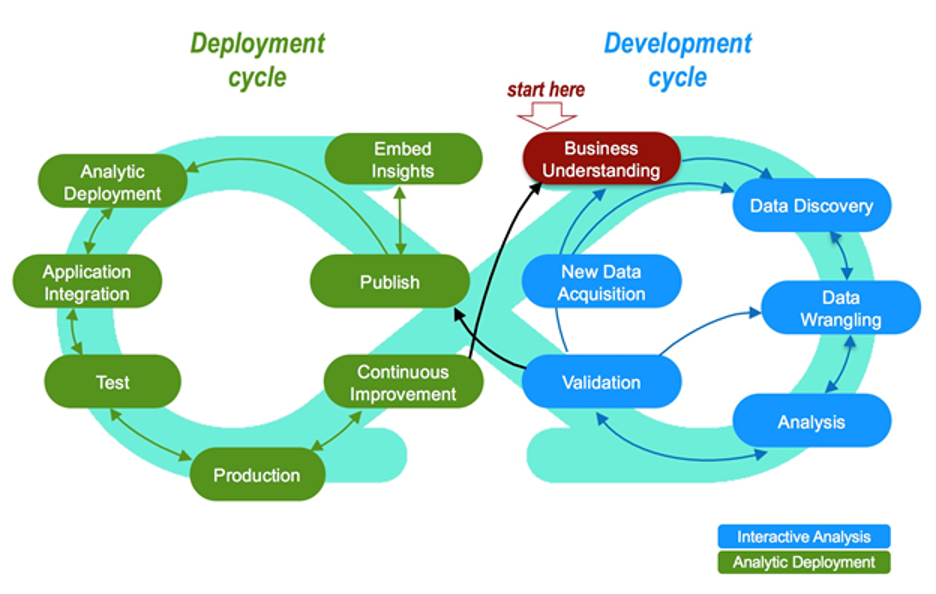
DevOps vs ModelOps
DevOps = software development + IT operations
- Manages deployments
- CI/CD of features, patches, updates, rollbacks
- Agile vs waterfall
ModelOps = data modeling + deployment operations
- Java environments
- Use of containers
- Also C/C++ and legacy environments
- Model performance monitoring
The 4 Deployment Paradigms
Batch
- 80-90% of deployments
- Leverages databases and object storage
- Fast retrieval of stored predictions
Continuous/Streaming
- 10-15% of deployments
- Moderately fast scoring on new data
Real time
- 5-10% of deployments
- Usually using REST (Azure ML, SageMaker, containers)
Mobile
Latency Requirements
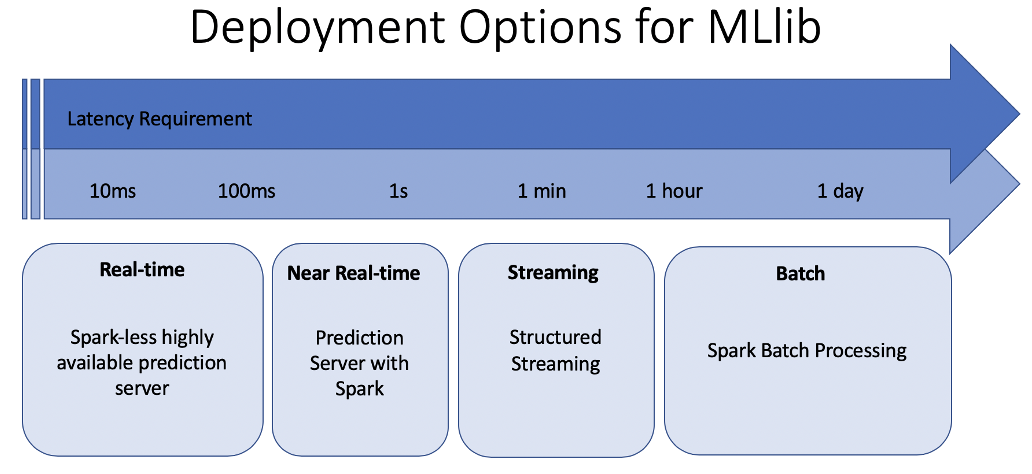
Deployment Requirements
All the (DevOps) things!
And then more things!
Core Requirements
Model architecture
ML pipeline w/ featurization logic
Monitoring + Alerting
CI/CD pipeline for automation
Testing framework (unit + integration)
Version control
Core+ Requirements
Model registry
Data and model drift
Interpretability
Reproducibility: data, code, environment, debugging
Security
Environment management
Specialized Requirements
Data dictionary
Cost management
A/B testing
Performance optimization
Deployment Architectures
Standards for each deployment paradigm
Managed by an admin
Clear responsibilities on maintenance in production
Who gets paged at 2 in the morning?
Architecture I
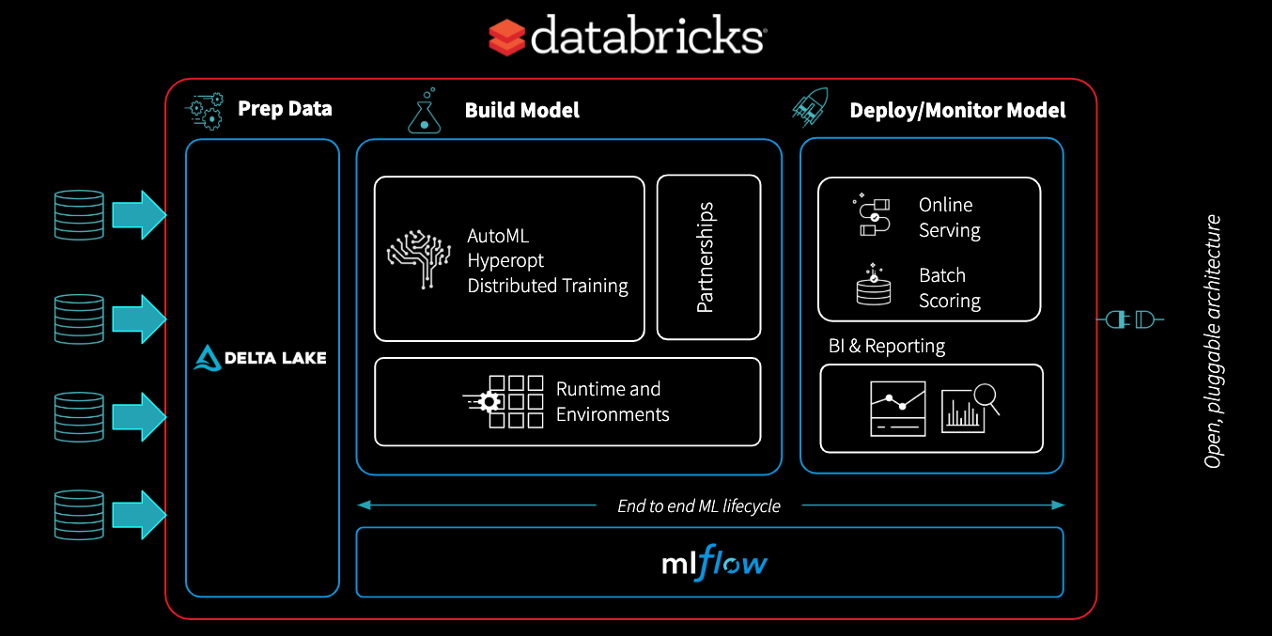
Architecture II
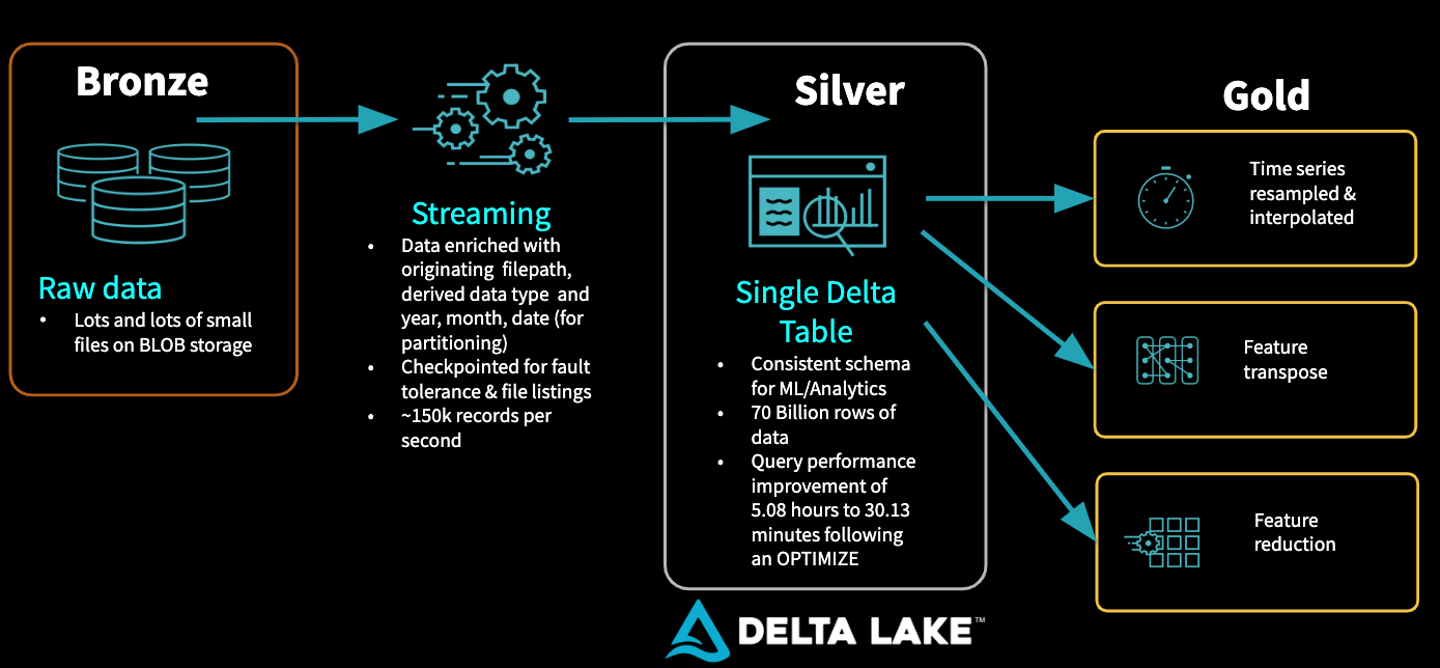
Architecture III
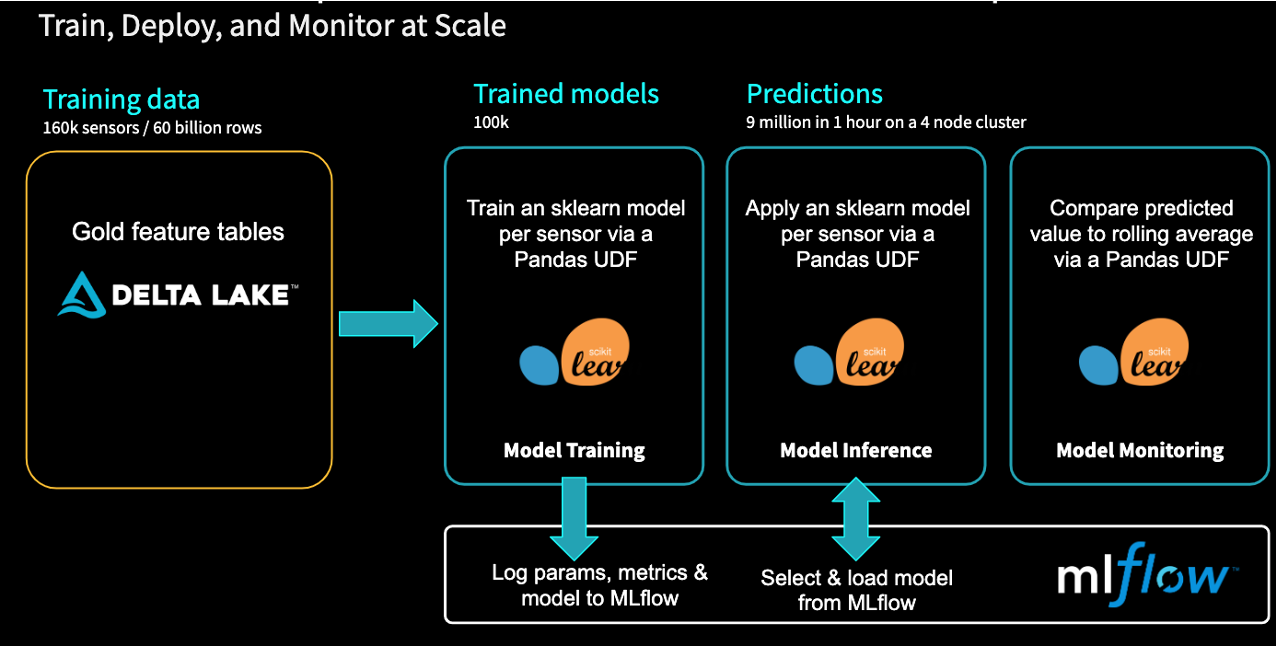
Delta + MLflow
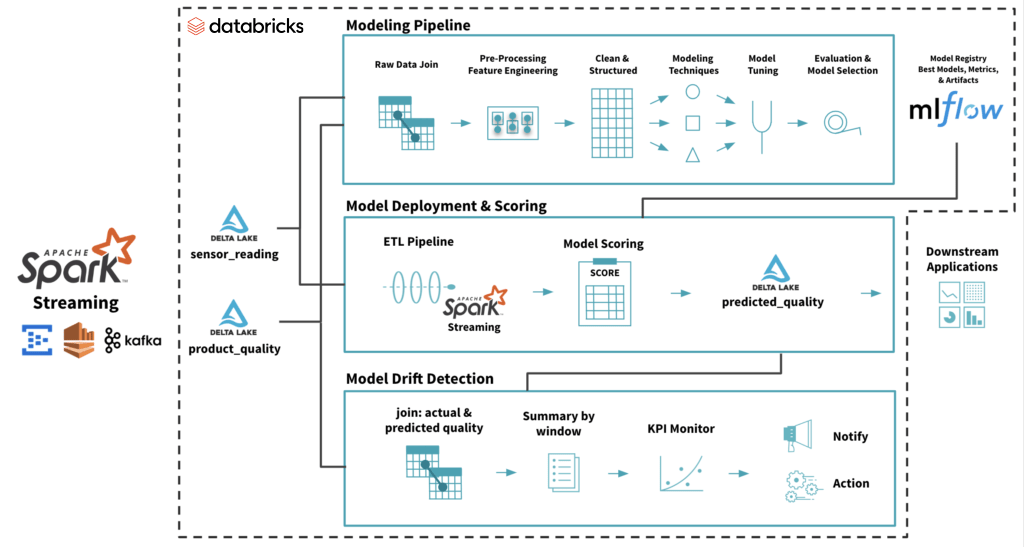
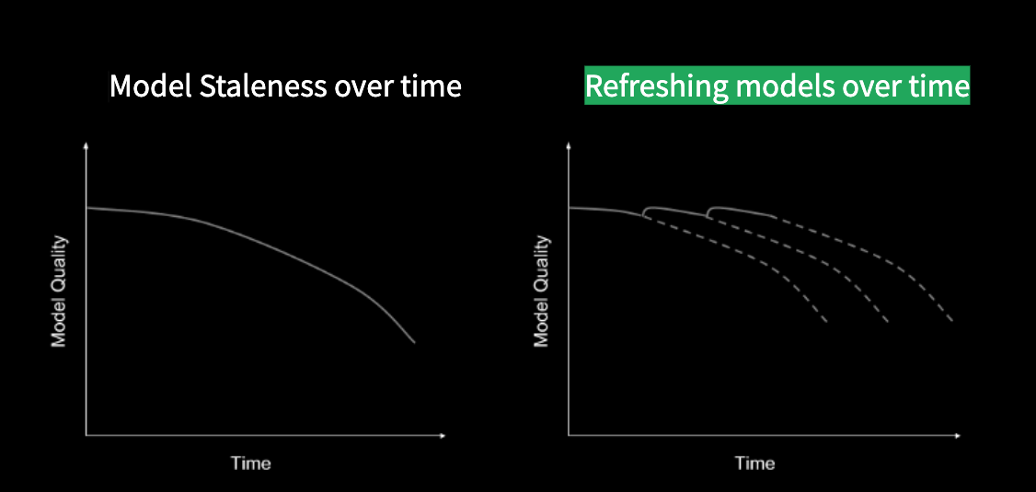
Other Issues
DL Optimization
Quantization: reduce precision of mathematical operations
- Train normally (e.g. on 64 bit numbers)
- Reduce to 32 or 16 bit for deployment
- Generally see 3x improvement
Weight pruning: reduce size of architecture
Model topography: retrain using different architectures
- e.g. compare MobileNet to VGG16
Featurization Logic
Apply the same logic to training and scoring data
Look into MLflow’s pyfunc
Confirm production data is available in training