Unified Analytics Engine
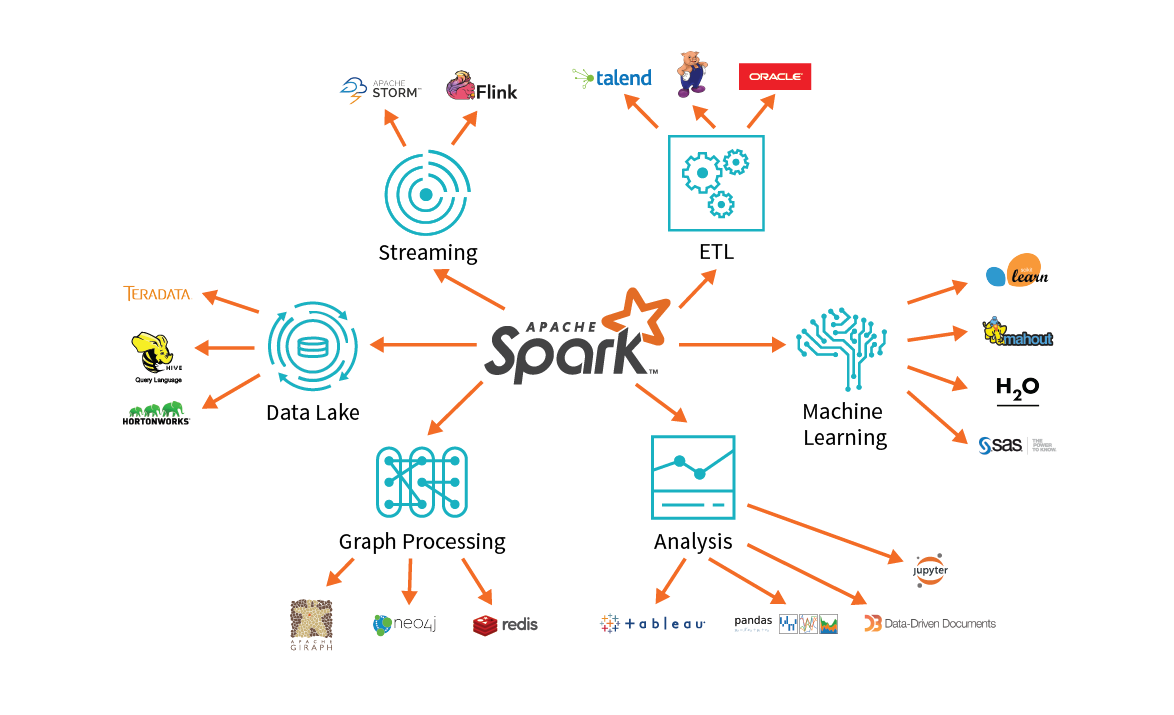
Apache Spark
Unified analytics engine for big data processing, with built-in modules for streaming, SQL, machine learning and graph processing
Research project at UC Berkeley in 2009
APIs: Scala, Java, Python, R, and SQL
Built by more than 1,400 developers from more than 200 companies
M&Ms
Spark Cluster
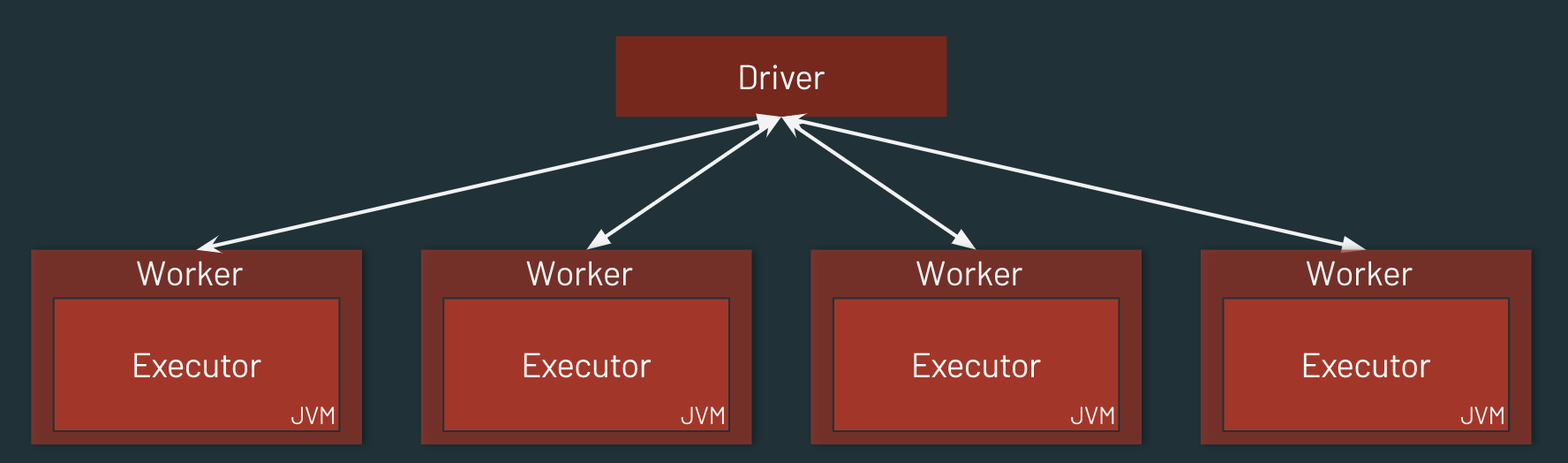
One Driver and many Executor JVMs
Spark APIs
RDD
DataFrame
Dataset
RDD
Resilient: Fault-tolerant
Distributed: Computed across multiple nodes
Dataset: Collection of partitioned data
Immutable once constructed
Track lineage information
Operations on collection of elements in parallel
| Transformations | Actions | ||
|---|---|---|---|
| Filter | Count | ||
| Sample | Take | ||
| Union | Collect | ||
DataFrame
Data with columns (built on RDDs)
Improved performance via optimizations
Datasets
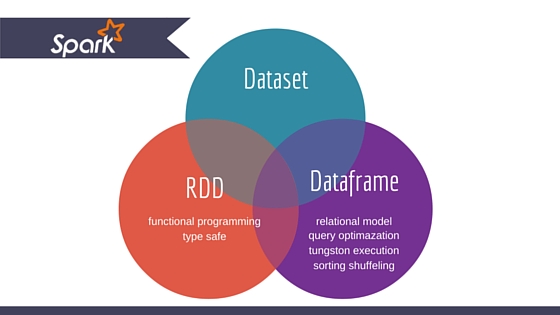
DataFrame vs. Dataset
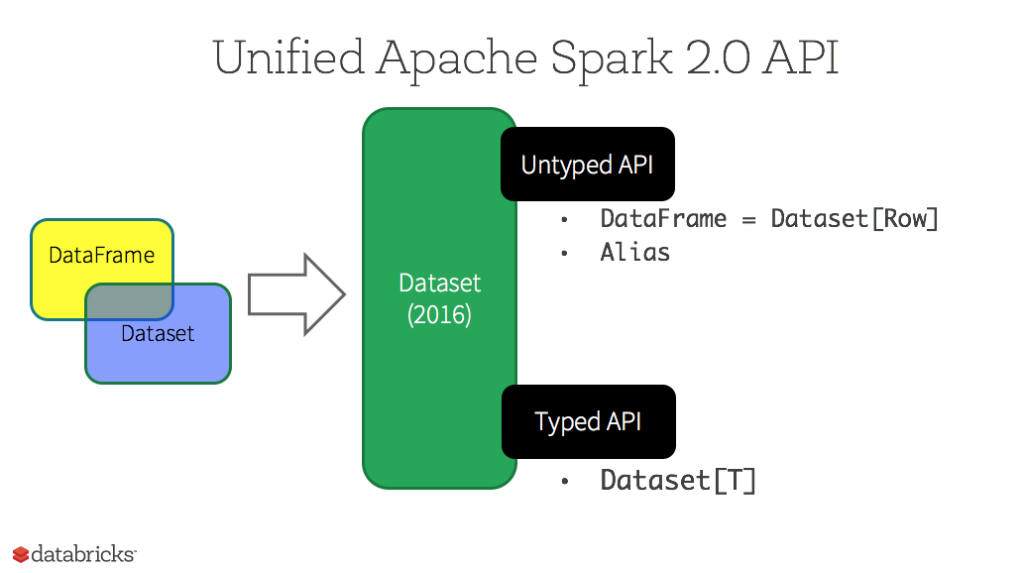
Why switch to DataFrames?
User-friendly API
dataRDD = sc.parallelize([("Jim", 20), ("Anne", 31), ("Jim", 30)])
# RDD
(dataRDD.map(lambda (x,y): (x, (y,1)))
.reduceByKey(lambda x,y: (x[0] +y[0], x[1] +y[1]))
.map(lambda (x, (y, z)): (x, y / z)))
dataDF = dataRDD.toDF(["name", "age"])
dataDF.groupBy("name").agg(avg("age"))
Why switch to DataFrames?
- SQL/DataFrame queries
- Tungsten and Catalyst optimizations
- Uniform APIs across languages
User-friendly API
Benefits:
Spark DataFrame Execution
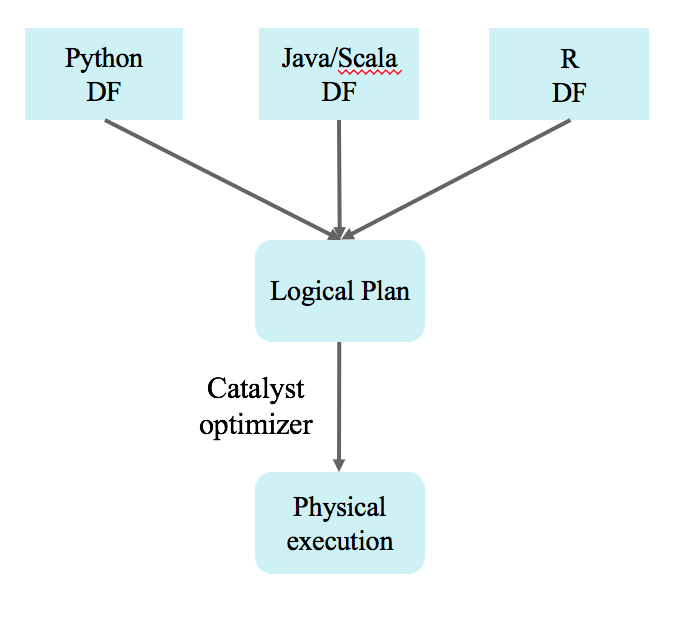
Wrapper to create logical plan
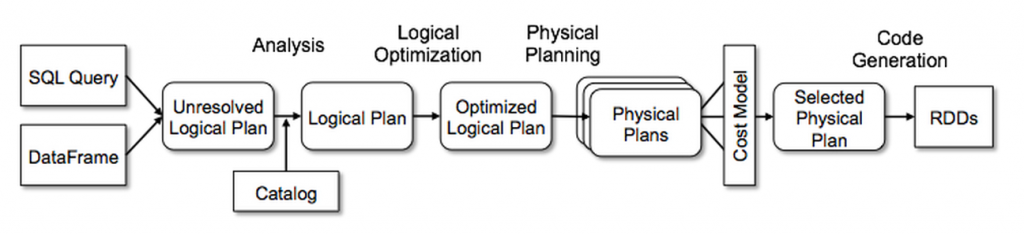
Catalyst: Under the Hood
Still not convinced?
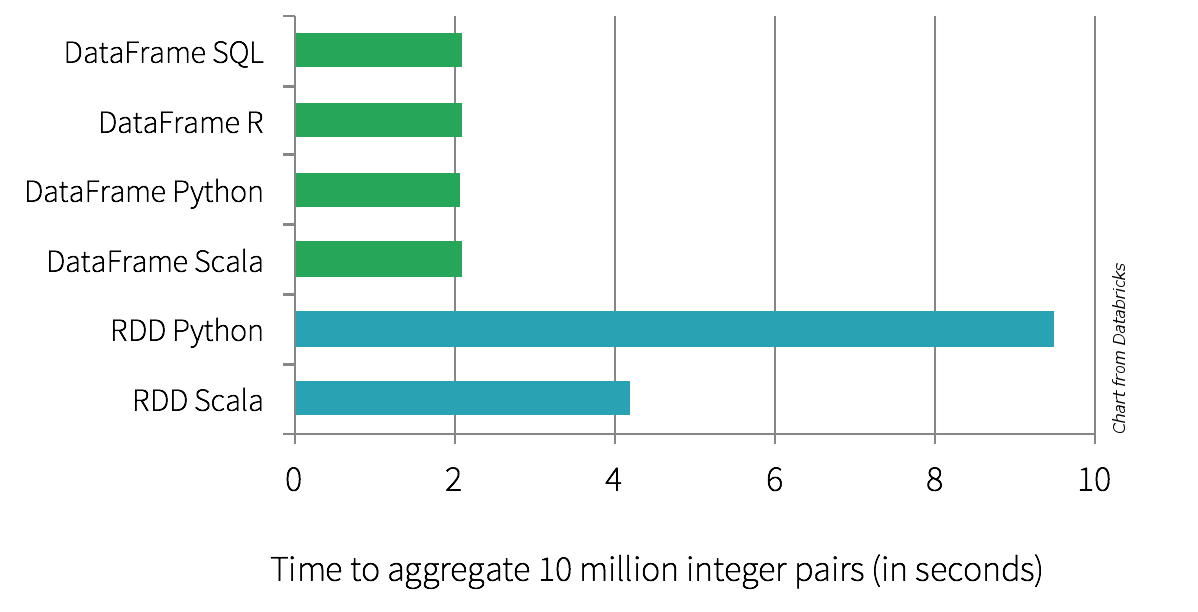
Structured APIs in Spark
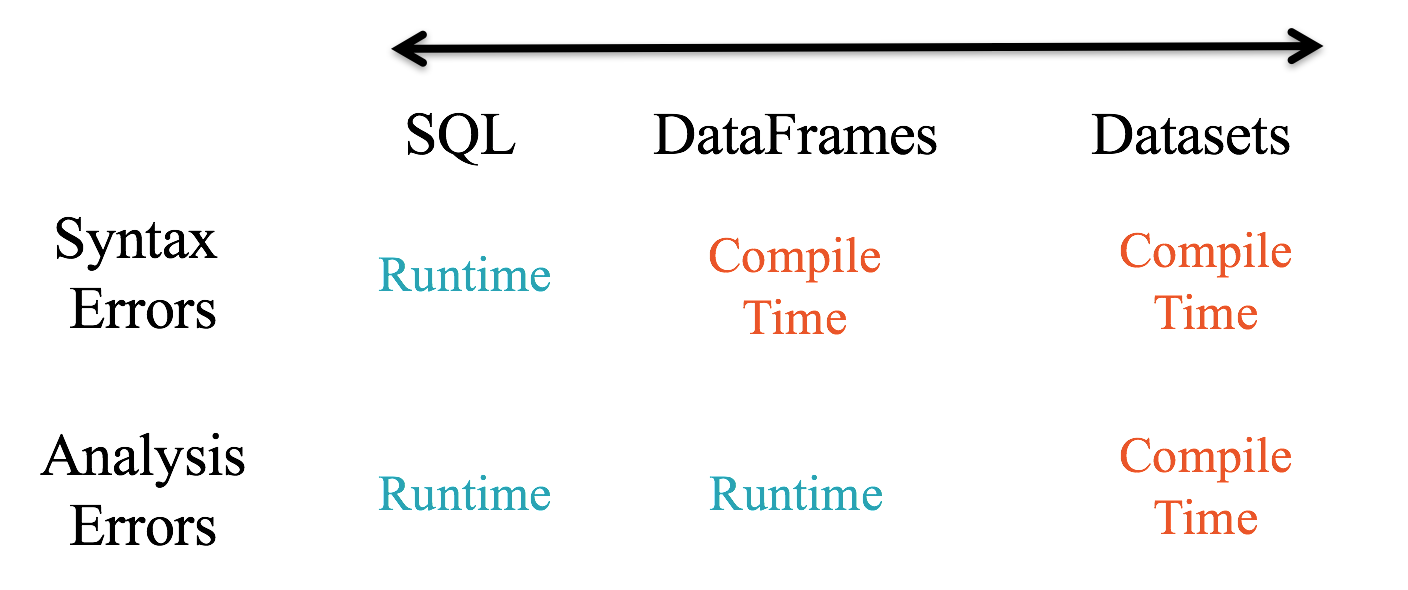
Spark vs MapReduce
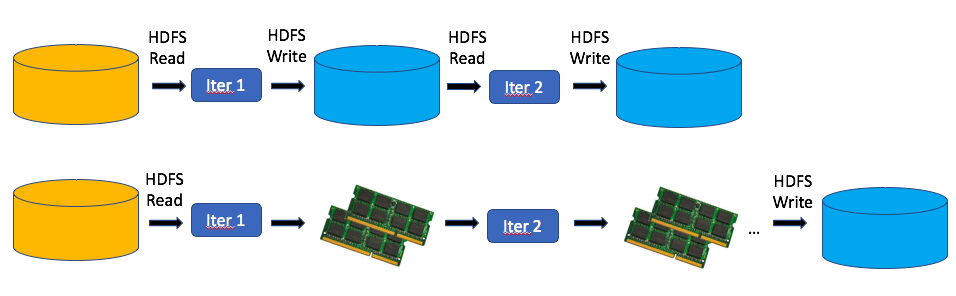
When to use Spark?
Scale out: Model or data too large to process on a single machine
Speed up: Benefit from faster results